Collector功能
Collector顾名思义是负责数据收集的,它负责搜集来自OpenStack其他组件(如Nova,Glance,Cinder等)的Notification信息,以及从Compute Agent和Central Agent发送来的数据,然后将这些数据存储在数据库中。
PubSubHubbub
PubSubHubbub是Google推出的一个基于Web-hook方式的解决方案,它其实是RSS的改进。它具体要解决的是RSS效率低和压力大的问题,有一个Go real time with pubsubhubbub and feeds讲的挺清楚
Tim的这篇博客也讲了它的机制,其中有这个图:
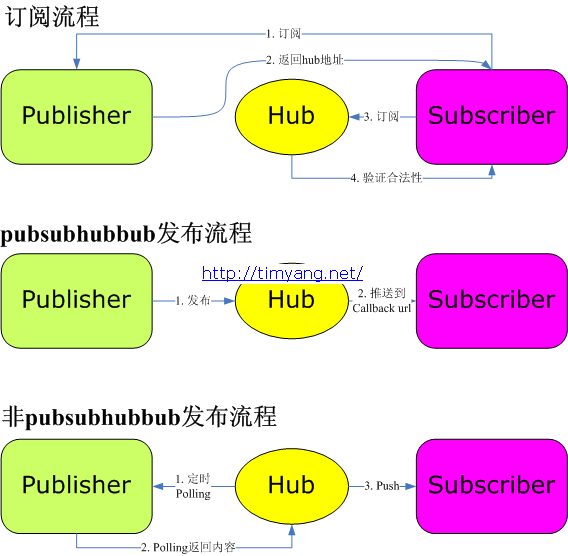
一个PubSubHubbub的大致流程如下:
- Sub找Pub订阅内容,Pub将Hub的地址发给Sub,告诉Sub:你以后找它要内容去
- Sub将自己要订阅的地址发给Hub,并在Hub那里注册了一个Callback函数,以后有新内容麻烦给Callback就好啦
- Hub可以主动,也可以被动的从Pub那里获得内容,然后再分发给在自己这里注册的Sub
图中可以看到,有这么几个关键部分,在Ceilometer中,它们对应如下:
- Publisher 内容提供方,OpenStack的各组件和Agent模块的角色
- Subscriber 内容订阅方,Collector的角色
- Hub 中转,Collector也充当了这个角色
Collector代码原理
有些相思代码在之前的OpenStack Ceilometer Compute Agent源码解读讲过
这里只写和collector有关的
入口函数
Collector的核心功能在ceilometer.collector.service:CollectorService中,它是OpenStack的Service服务,启动以后从initialize_service_hook()开始运行
def initialize_service_hook(self, service):
self.pipeline_manager = pipeline.setup_pipeline(
transformer.TransformerExtensionManager(
'ceilometer.transformer',
),
publisher.PublisherExtensionManager(
'ceilometer.publisher',
),
)
self.notification_manager = \
extension_manager.ActivatedExtensionManager(
namespace=self.COLLECTOR_NAMESPACE,
disabled_names=
cfg.CONF.collector.disabled_notification_listeners,
)
self.notification_manager.map(self._setup_subscription)
self.conn.create_worker(
cfg.CONF.publisher_meter.metering_topic,
rpc_dispatcher.RpcDispatcher([self]),
'ceilometer.collector.' + cfg.CONF.publisher_meter.metering_topic,
)
这里只说重点的,self.notification_manager是导入所有可用的内容的处理对象,从setup.cfg中可以找到
ceilometer.collector =
instance = ceilometer.compute.notifications:Instance
instance_flavor = ceilometer.compute.notifications:InstanceFlavor
instance_delete = ceilometer.compute.notifications:InstanceDelete
...
订阅内容
接着self.notification_manager.map(self._setup_subscription)要对这些对象进行配置,其实就相当于PubSubHubbub中的订阅了
def _setup_subscription(self, ext, *args, **kwds):
handler = ext.obj
for exchange_topic in handler.get_exchange_topics(cfg.CONF):
for topic in exchange_topic.topics:
self.conn.join_consumer_pool(
callback=self.process_notification,
pool_name='ceilometer.notifications',
topic=topic,
exchange_name=exchange_topic.exchange,
)
回调函数
这里_setup_subscription()讲每一个订阅对象都join_consumer_pool,即在AMQP中接收这些订阅相关topic的内容,然后指定了callback函数为self.process_notification
def process_notification(self, notification):
self.notification_manager.map(self._process_notification_for_ext,
notification=notification,
)
def _process_notification_for_ext(self, ext, notification):
handler = ext.obj
if notification['event_type'] in handler.get_event_types():
ctxt = context.get_admin_context()
with self.pipeline_manager.publisher(ctxt,
cfg.CONF.counter_source) as p:
p(list(handler.process_notification(notification)))
callback在执行后会调用这些notification中的process_notification(),它的作用是对不同的消息进行不同处理,因为从Nova,Glance等组件发来的消息Collector不一定都读的懂
处理内容
处理好的消息还是会通过Pipeline发送到AMQP中,然后和Agent直接发来的消息类似,Collector接收并交给
def record_metering_data(self, context, data):
for meter in data:
if meter.get('timestamp'):
ts = timeutils.parse_isotime(meter['timestamp'])
meter['timestamp'] = timeutils.normalize_time(ts)
self.storage_conn.record_metering_data(meter)
来处理,其实相当于自己给自己通过AMQP发了一条信息,这也就能看出,其实Collector充当了Hub和Sub双重身份
总结
Collector相对来说不是很复杂,了解了PubSubHubbub后再看就相对简单了。
这里没有详细说数据存储部分,因为存储和API调用部分联系比较紧密,留给存储部分再讲吧